This article shares a case study of applying a systemic approach to software production that supported the deployment acceleration of a monolith from 3 months to 3 days without microservices in a global e-retailer of 650m€ annual turnover and 95% of online sales.
“Accelerate” was one of the recurring words we got from business executives to keep the business competitive with fierce competition, scarce resources, and increasing uncertainty. With many options to look at, we had to step back on our production system to architect an incremental transformation.
The challenge was to avoid short-term shortcuts and single-solutions like “APis” or “Microservices” that would have kept us busy for many months, shown few results in the short-term, but created more problems in the mid-term especially with more complexity and technical debt.
We had to develop our software production system so that software changes were frequent, reliable and efficient to sustain our business in its reinvention. It means we had to go beneath superficial analysis to develop more precise actions and solutions.
A business-critical legacy monolith
We had a “legacy” system heritage that supported the business until now for about 10 countries for a multi-million retail business. A positive point for us had been to roll-out this system across all countries simplifying our current applicational landscape.
Originally based in AS400 and COBOL (yes, that’s the green screens), the legacy had evolved to a more modern stack (J2EE, jenkins, central logging), but was still having the datastore and key business processes in the realm of batches and obscure acronyms.
The development and deployment process was quite painful, requiring strong coordination efforts between development and operations teams, with multiple coordination meetings, arbitration, and frustration for who got the next release spot. That process was only delivering changes once per quarter, followed by weeks of bug fixing.
The legacy has done the job but it became a business limiting factor as:
- Business initiatives were delayed by months
- Training and support efforts were increasing
- Operational complexity was only growing.
While the competition was starting to accelerate their rate of changes, we started to have a serious business pressure to find drastic improvements in order to “Accelerate”. The difficult point is that it was not only about acceleration, but also having more sustainable foundations that would not accumulate even more technical debt.
The efforts made to modernize programming languages and automate deployment steps with solutions like Jenkins did help but did not make a significant difference in software delivery outcomes. We needed a different approach.
Clarifying the problem space
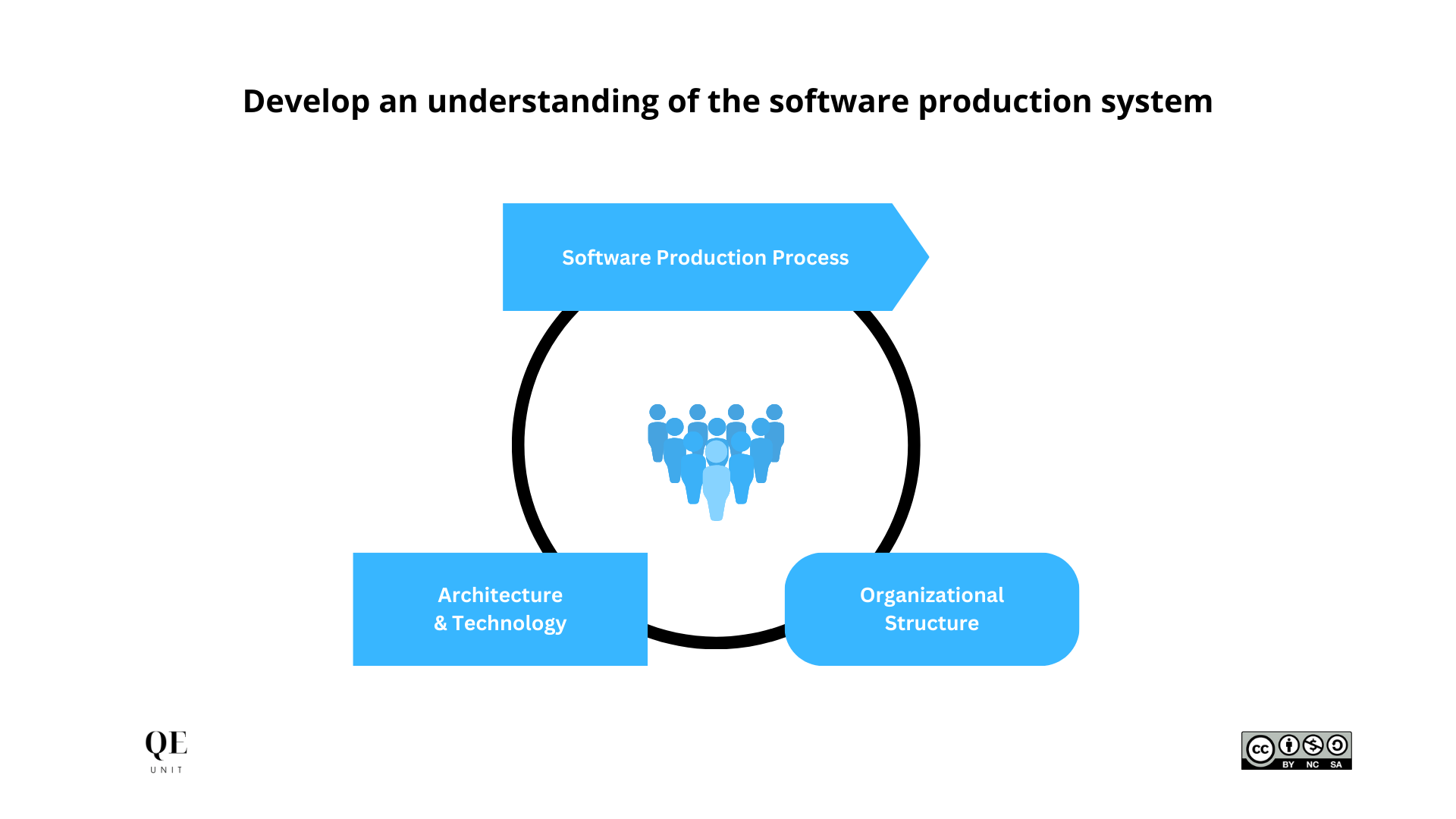
We recognized that engineering problems are complex to solve and rarely require a single action or one technology to make the difference. Our approach was to map the 3P of “People, Process, Technology” to develop an inclusive perspective of our ecosystem.
We looked more precisely at:
- Software production process
- Architecture and technology maps
- Organizational structure design.
Software production process
This first step consisted in identifying the most structuring activities our team was taking at each step of the software lifecycle, to then map the pains we agreed on in two categories of “Quality pains” and “Speed pains”.
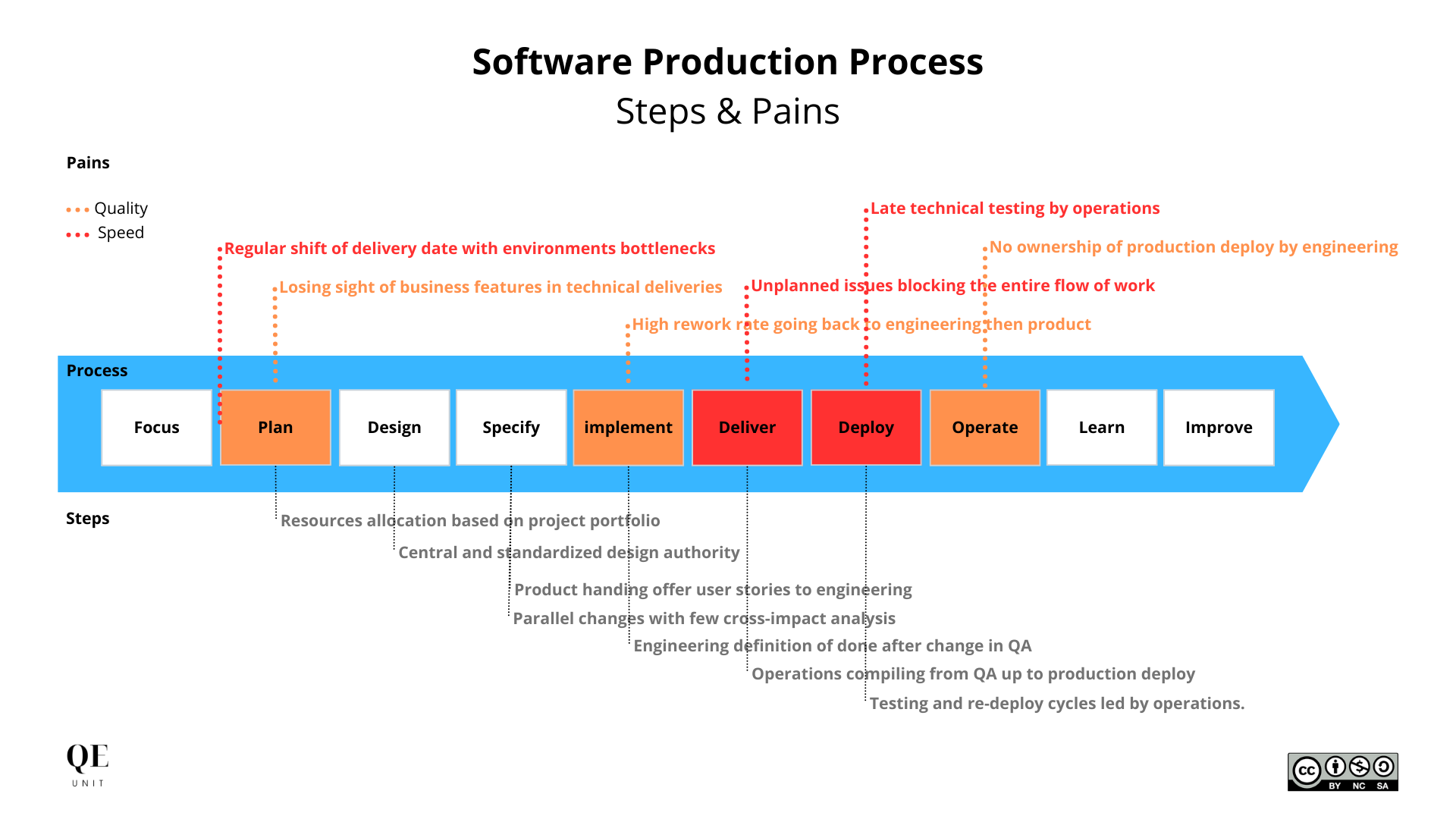
The collaborative exercise and shared visualization was useful in aligning everyone on the activities we were taking across teams, and the different impacts they may have a different point in time.
The key high-level steps of the software production process were:
- Resources allocation based on project portfolio
- Product handing offer user stories to engineering
- Parallel changes with few cross-impact analysis
- Central and standardized design authority
- Engineering definition of done after change in QA
- Operations compiling from QA up to production deploy
- Testing and re-deploy cycles led by operations.
With different pains we were suffering on a regular basis:
- Losing sight of business features in technical deliveries
- Regular shift of delivery date with environments bottlenecks
- Late technical testing by operations
- No ownership of production deploy by engineering
- High rework rate going back to engineering then product
- Unplanned issues blocking the entire flow of work.
Architecture and technology maps
The material context in which actors are producing software is equally important to understand the potential performance problem. Like an artisan can be much more productive with the right information, tooling, and automation, so do software engineers.
We mapped the architecture and technology items plus pains in a schema similar to the one below. If you start to see that structuring quality issues of architecture are impacting your software delivery quality and speed, that’s what we started to draw.
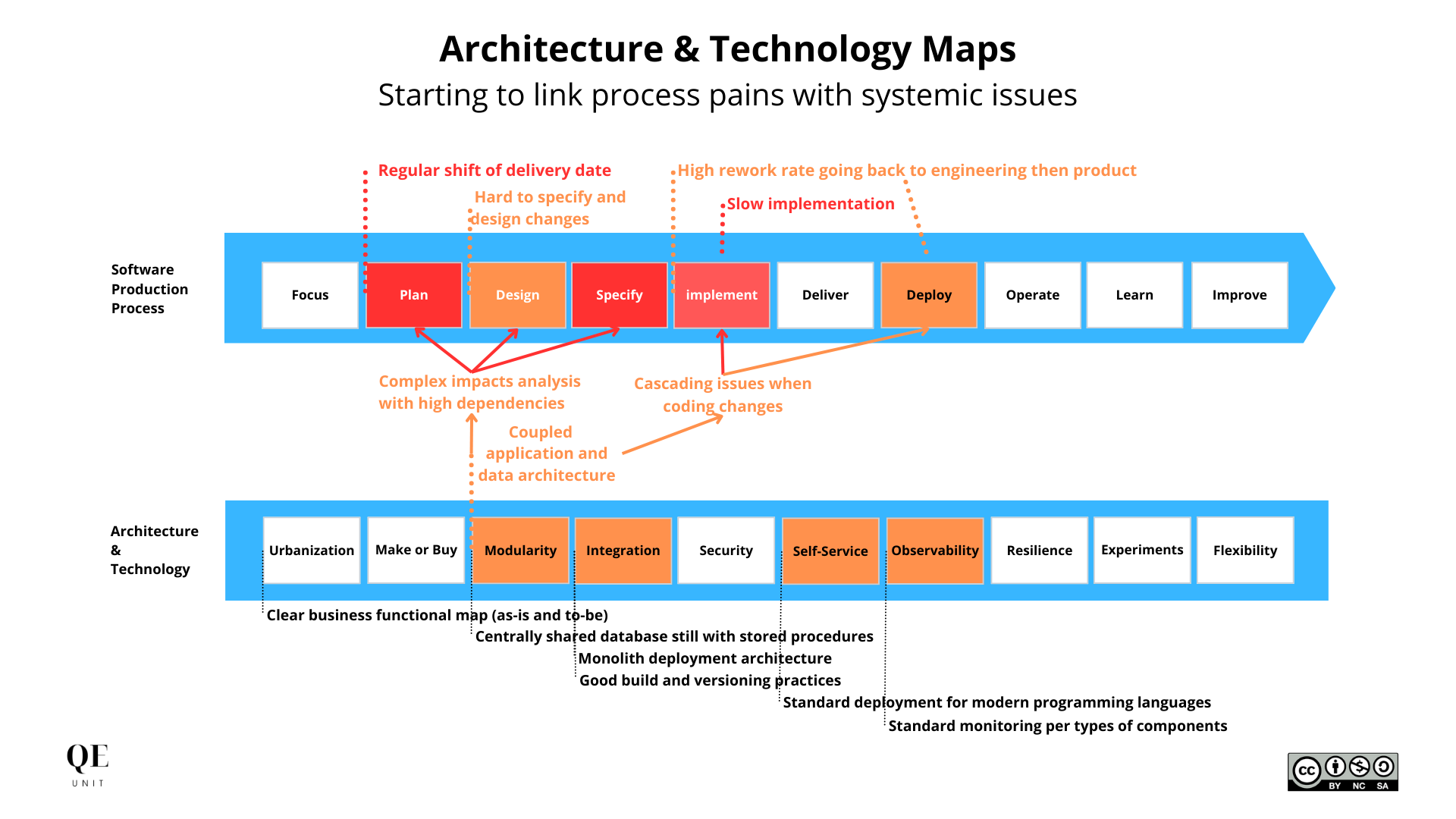
The key elements of architecture & technology context were:
- Clear business functional map (as-is and to-be)
- Coupled application and data architecture
- Monolith deployment architecture
- Centrally shared database still with stored procedures
- Good build and versioning practices
- Standard deployment for modern programming languages
- Poor testing solutions whatever unit, integration, or functional
- Standard monitoring per types of components.
Yet also with specific pains:
- Complex impacts analysis with high dependencies
- Nightmare and costly estimate to update data models
- Poor automation of major changes and exceptions handling
- Deployments with down-time with few observability
- Low ability to run applications from a developer environment.
Organizational structure design
The choices of perimeter and relationships in organizational charts directly impact the power given to certain areas. Indirectly, the organizational structure also influences the ratio of interaction between actors that we may want to happen depending on goals.
In our case, the mapping revealed structuring upstream issues in terms of organizational design negatively impacting our organizational performance, but also our software production. It was not for no reason that we had “No ownership of production deploy by engineering” and “Technical testing done by operations team lacking a functional link”.
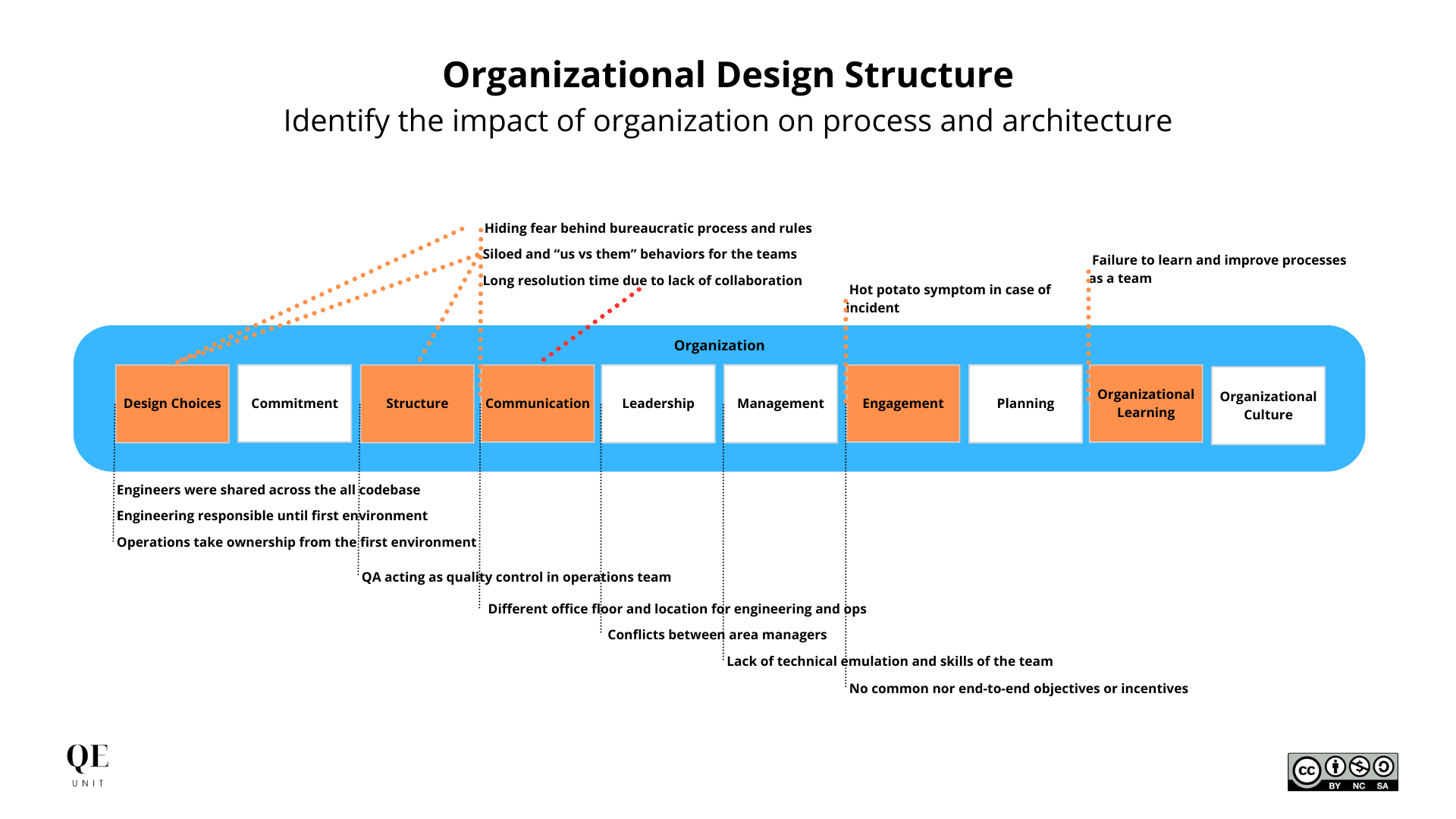
In our context, the organizational design resulted in:
- Engineers were shared across the all codebase
- Engineering responsible until first environment
- Operations take ownership from the first environment
- QA acting as quality control in operations team
- No common nor end-to-end objectives or incentives
- Lack of technical emulation and skills of the team
- Different office floor and location for engineering and ops
- Conflicts between area managers.
Alongside with key pains:
- Hiding fear behind bureaucratic process and rules
- Hot potato symptom in case of incident
- Siloed and “us vs them” behaviors for the teams
- Long resolution time due to lack of collaboration
- Failure to learn and improve processes as a team.
We were even more convinced that the problem was not only about technology.
Working on the solution space
Equipped with a better visualization of our existing production system, we still knew iterations would be required on the solution space and started to draw out an action plan focusing on solutions.
At that stage, the main problems identified were:
- Lack of modularity in application and data layers
- Missing solutions for environment and testing
- Lack of standardization and automation.
- Siloed organizational model and collaboration
- Lack of understanding and interactions between teams.
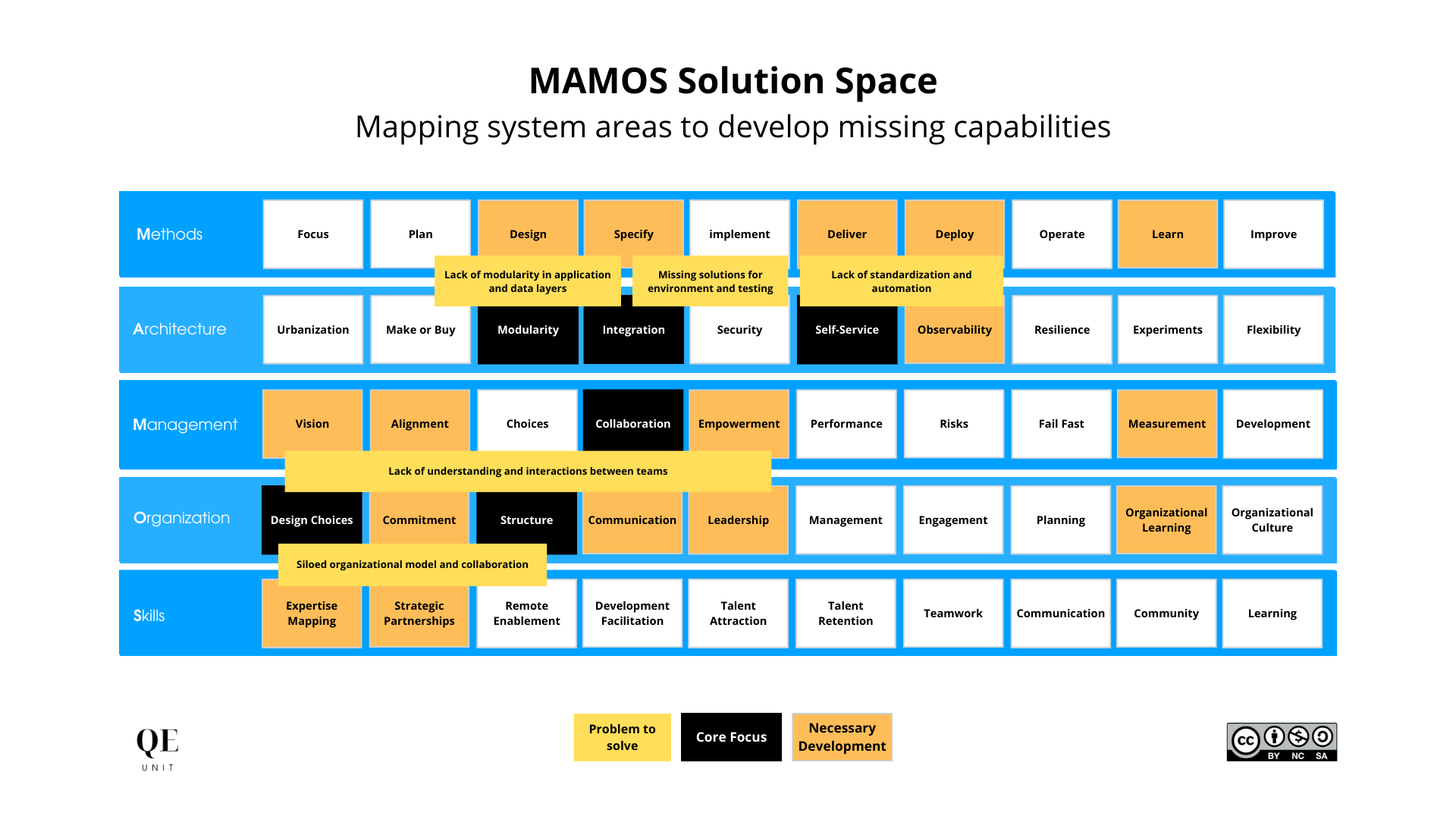
The above MAMOS Solution Space map summarized the key issues on the entire software production system focusing on the capabilities to align horizontally and vertically to solve particular problems.
In this case, it helped us to define three key priorities to accelerate:
- Architect independent flows of iterations
- Develop modularity in application and data layers
- Standardize solutions for automation & environments.
Architect independent flows of iterations
Multiple teams collaborating on the same codebase can only accelerate when they can abstract from other changes going on, something that becomes harder when the codebase and the team is growing. That’s where modularity becomes a key requirement that is not only achieved with technology.
Modularity can successfully separate concerns in software having an alignment of modular software architecture, teams, and delivery lanes. Having one of these elements misaligned will create friction in the system, like the ones we were feeling with bottlenecks of code changes in shared delivery lanes.
We architected independent flows of iterations by evolving from:
- Monolith to Modular monolith software architecture
- Shared engineering pool to domain-aligned teams
- Technical release lanes to functional release trains.
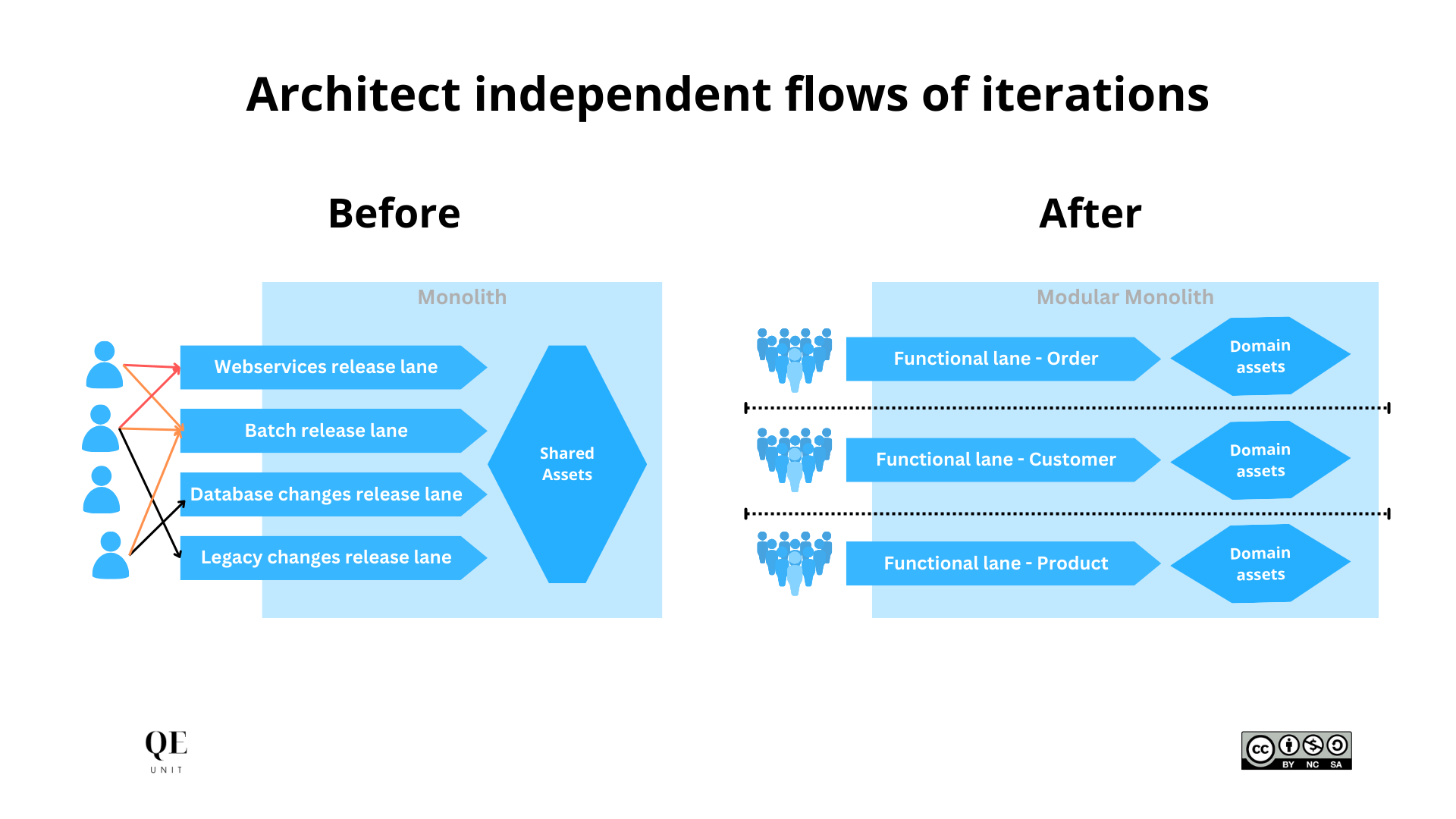
Monolith to Modular monolith software architecture
Looking at the software modularity options, we had different macro options:
- Keep the monolith & improve what we can
- Evolve to a modular monolith developing domains scope
- Build new needs in independent services (wherever macro/micro).
As for many companies, we had constraints and challenges to keep in mind:
- The business had to keep evolving as fast as we can
- Investments and resources were limited for improvement
- Results and intermediate valuable steps had to be reached.

We decided that the most adequate option would be to invest in option 2 evolving to a modular monolith as the business complexity was already important, with a high risk of not being able to contain it in a monolith. The modular monolith had the advantage to push to industrialize our existing technology context, structuring our existing teams on the functional boundaries we would develop in modules.
The option 3 would have generated much more breaking changes with the additional efforts of isolation required we would have hardly supported with limited resources dedicated to our platform and technology scope. And budget being scarce, our money pot was already allocated to the monolith improvements activities.
Shared engineering pool to domain-aligned teams
On the organizational side, the existing engineering teams consisted of a pool of software engineers and project managers dynamically allocated depending on needs. While this shared approach was effective in a small codebase and tean with few conflicting changes, it had hit the limitations with a growing organization.
The key change was to structure the team in cross-functional teams aligned on the business domain scope. The main list was derived directly from the business organization to improve alignment as upstream as possible. We ended up with 7 cross-functional teams (customer, order, …) with a clear functional perimeter but a clearly misaligned application and data perimeters.
The first priorities for each domain team was to identify its existing components, functions and data to allocate the ownership to each team. From there, we had to develop modularity with changes implementing properly abstracted functional interfaces that isolated functions and data for independent streams of iteration.
Technical release lanes to functional release trains
The last part to architect for independent fast flow was to provide each cross-functional team with dedicated deployment lanes. Previously optimized from a technical perspective (e.g. batch or web services), waiting for a deployment slot was the day-to-day of most software engineers eager to deploy their changes.
The delivery lanes were standardized aligned on the 7 domain teams, giving them the flexibility to define releases with different technical components, also improving the business understanding of upcoming changes from a functional perspective. This change made a true difference in the deployment autonomy of each team but required good automation to avoid creating too much manual work in the operations team.
Develop modularity in application and data layers
The architecture of independent flows of iteration structured, we had to make sure to develop modularity on next changes going as part of the normal flow of iteration. That required a structuring investment in our software delivery process keeping the big picture of our entire system.
We identified 3 main changes:
- Strengthen the Design Authority on modularity and requirements
- Document explicit interfaces versus application functions & data
- Upskill our competencies in face of the evolution performed.
Strengthen the Design Authority on modularity and requirements
We had the chance to have a structured design authority everyone was familiar with. The main impulsion required was to develop a systematic review of modularity and requirements ensuring that the right design decisions were taken.
The first step was to define the guide to prepare the review for modularity and requirements.
Modularity required the team to have a set of functional, data, and flow schemes that allowed them to visualize the interactions and gauge the level of coupling. An application and component map was then used to highlight the as-is and proposed changes in face of the improved modularity, sometimes requiring extra work for new interfaces or consolidating spreaded data into a single module.
Requirements started with a simple approach focusing on the functional and integration test plan. One important point was to build up the suite of requirements over changes, avoiding a project approach where all requirements are defined again and again for each change. In addition, the most important requirements had to be automated as part of the next delivery to build up the non-regression test suite.
Document explicit interfaces versus application functions & data
The level of complexity of the existing system was so important that we were not able to document the functions and data relationships with components through the design authority preparation. We decided to dedicate a continuous time each week per domain team to proactively document domains that would be most subject to changes.
That step required a clear ownership of each domain team leader with a shared format across teams for the referential. That way, we were able to foster collaboration and identify cross-team impacts with a shared model that each team could build upon.
Upskill our competencies in face of the evolution performed
This last area consisted of investing in the following MAMOS areas:
- Expertises mapping to understand our gap and potential
- Strategic partnerships to get missing expertise when needed
- Teamwork to favor informal sharing and community interactions.
Each of these areas helped us at different moments.
While preparing, expertises mapping gave us the gaps of skills we had to develop in given cross-functional or infrastructure team, and helped us identified internal potential that can move to a more adequate position we would need
While starting, strategic partnerships enabled us to leverage external expertise to set up or improved more quickly new processes, and coach the team in new ways of working with good examples right from the start
While improving, teamwork acts as a complementary force outside of the main software production process to develop inter-team collaboration, sharing of experiences, and allowing more junior profiles to grow more quickly.
Standardize solutions for automation & environments
The last block of investment was on three areas of MAMOS:
- Automation of build, version, release, deployments, tests steps
- Testing resources from environments, testing and data refresh
- Integration with standard infrastructure and app components.
Automation of build, version, release, deployments, tests steps
The automation of the delivery pipeline was necessary to support the increasing demands for deployments from functional release trains. As we had a standard coding foundation in the monolith, the work focused mostly on the automation of the different steps from build, versioning to release and deployment across environments.
That stage required developing important referential that were not centrally managed like the list of application environments, endpoints, versions. We centralized this information in an internal application called “Index” that also enabled us to have a central portal for internal users to access applications.
Testing resources from environments, testing and data refresh
These standard foundations were accelerators when we started the test automation and environment provisioning efforts. Testing required our QA automation profiles to invest in test design and non-regression suite building to support their cross-functional teams in their acceleration effort. A team leader was here responsible to develop shared best practices.
The environment provisioning theme was more tricky due to the effort of automation required to make a new environment available in terms of configuration and integration. We started by standardizing each test environment usage and making them stable with test data refresh anonymized from production, and a set of fixed test data in complement.
From there, we were able to enable cross-functional teams to test manually and develop their test automation suites in much more stable environments. Afterwards, thanks to the infrastructure as code capabilities developed we proposed for specific needs to have on-demand environments with a shorter refresh ratio.
Integration with standard infrastructure and app components
Setting standard infrastructure and application components with infrastructure as code and an on-demand development environment. Solutions like Puppet, Chef, and Vagrant were implemented and industrialized within our tech ecosystem.
From there, the automation of the entire steps of deployments with stable technology components—including testing—enables developers to focus better on producing modular code. We pursued the development of our internal test automation platform Cerberus Testing for all applications with native CI/CD plugins, functional and integration tests.
Outputs & Outcomes
Our transformation effort was supported by metrics used in retrospective and regular communication of our progress.
We divided the indicators in these known categories:
- Outputs usually compiled from unitary metrics
- Outcomes focusing on key results of given activities
- Impact representing business or customer value.
MAMOS provides us with a maturity model to assess the progress of our transformation journey on the different performance axes.
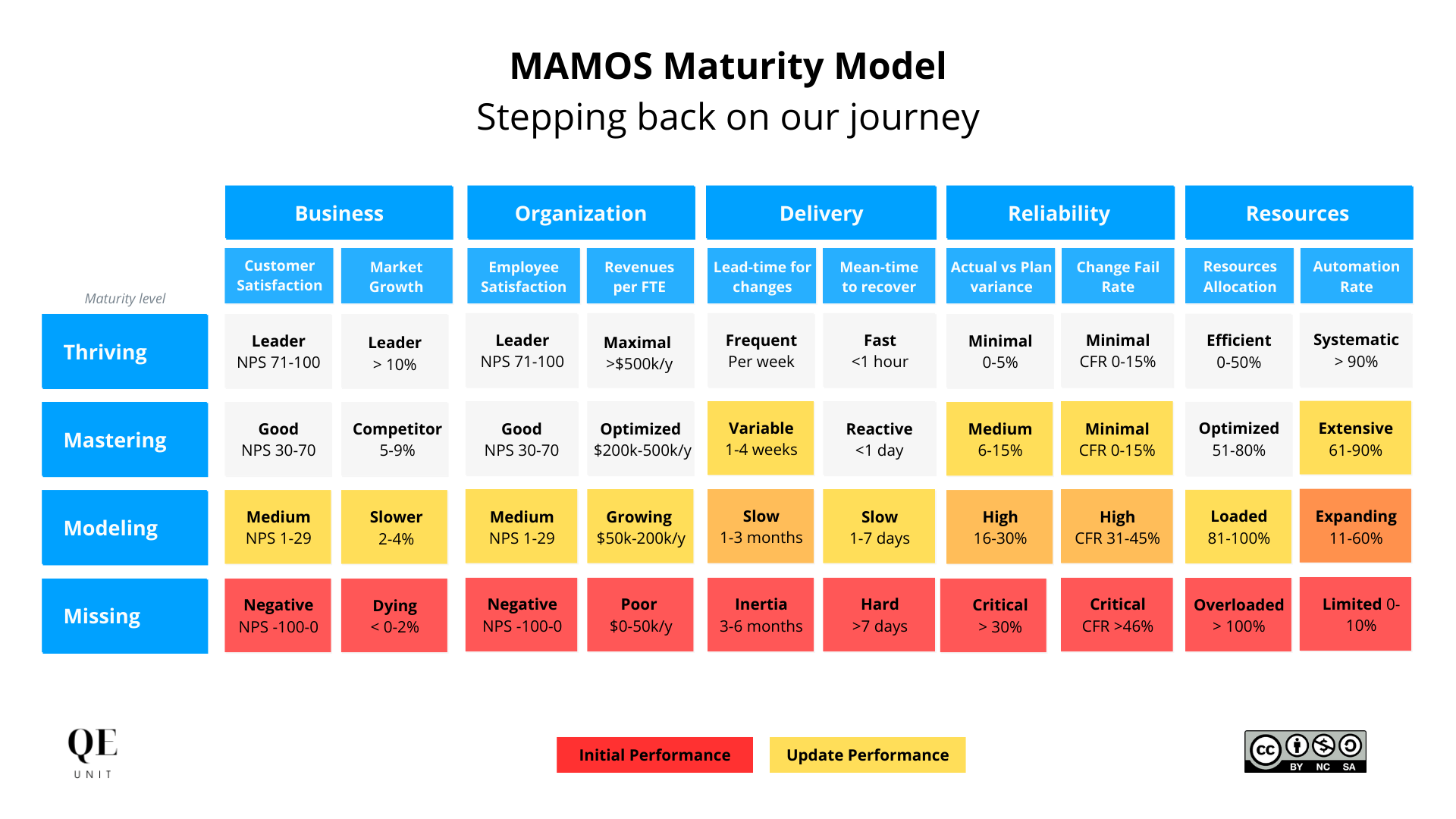
Outputs
The following outputs were the most relevant in our context:
- Deployments frequency from 3 months to 3 weeks in the first 6 months, to then reduce up to 3 days in the first year
- Number of automated tests executed at each delivery grew from 45 to 845 overall with a median of 125 per module
- Defects reduced drastically with less than 2% detected in production and now a capability to detect 70% before they enter the lane.
Outcomes
As for outcomes, the changes did improved key software production indicators:
- Lead-time for changes reduced the amount of business needs in the backlog to start delivering new features in weeks or 1-2 months
- Change Fail Rate evolved from more than 30% to a range of 3-7% thanks to better environments, testing, monitoring
- Employee satisfaction grew with our engineering NPS with less hotline, rework, and extra hours being less saturated.
Impacts
Over time, the improvements positively contributed to our business with:
- Delivery of new business initiatives with few delays
- Reduction of software training and application support
- More stable operations with better functional alignment.
Accelerate with MAMOS
Our acceleration journey did require structuring effort to evolve from 3 months to 3 days but with a focused and continuous approach rather than a one-shot disruption. The initial investment in the problem space and the definition of systemic solutions were key to sustain and build upon our changes with stable intermediate steps.
This systemic approach consolidated in MAMOS is the one we defend in the QE Unit, aligning the entire system to make software production our best competitive advantage. More than a technology transformation, it was an ecosystem evolution recognizing the need to consider the big picture with the actors at the center. Microservices were indeed not the first solution to implement in our given, and we later evolved first to a Macroservices model leveraging our modular and standard foundations.
Would the results have been better with another approach? Hard to guess. Mine is that we would have created more problems that solutions missing more robust foundations in the different areas of our software production system.
Now, develop the understanding of your software production system with MAMOS.
References
Antoine CRASKE (2022), Quality Engineering Focusing On The Pipeline. QE Unit.