
QAOps is an emerging practice to incorporate quality as part of the software development lifecycle.
The approach complements the existing DevOps ones, emphasizing the quality perspective, starting from the business up to the operations.
This round-table focuses on the Observability Pipeline, a concept combining the practice of monitoring, alerting, and data engineering.
I thanks each participant for their participation and contribution :
- Eduardo Piairo, Operations Director at Deeper Insights
- Ricardo Castro, Senior Site Reliability Engineering at Farfetch
- Pedro Esteves, Senior Tech Lead
- Luís Bastião Silva, CTO at BMD Software
This article is the summary of the key points we identify during our sharing,
Join the QE Unit to access more community content.
Observability, a Foundation of QAOps
QAOps is about improving the impact of quality through the entire software development. The “Ops” part does not restrict its prism to the operational aspect; it starts from the business and users’ perspective, even before coding. So, where does Observability fits? We have to start with why.
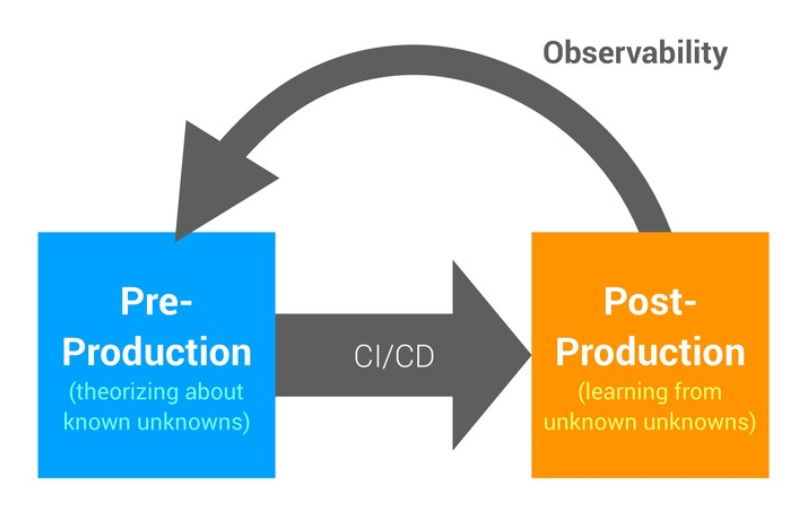
As a contributor to the business, our goal is to create more value. Therefore, measurement becomes a requirement, “We can’t improve what we can’t measure”. Observability is the practice of understanding a system from its external data points, hence making it “Observable”.
A disclaimer: a lot of things are not measurable, unfortunately and for now.
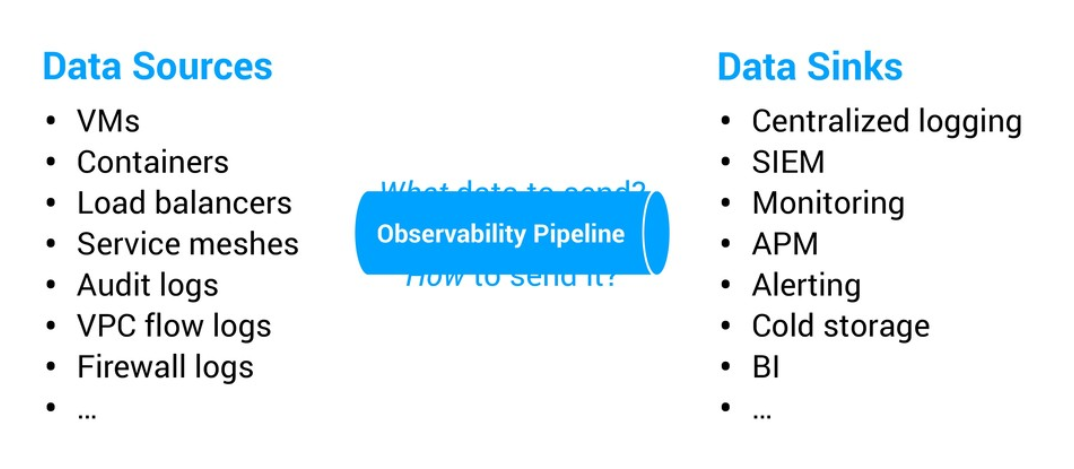
Observability does not work by itself, at least for now. We have to create the data points, collect them and make them worthwhile. These three steps are found in data engineering architectures, explaining the term “Observability Pipeline”. In our case, we collect and process a variety of metrics, logs, and traces.
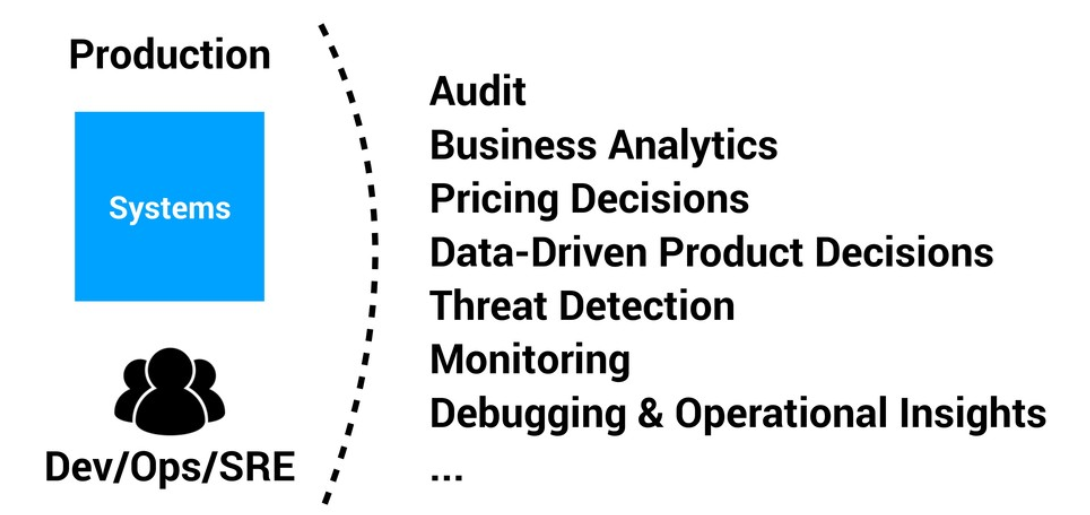
As for QAOps, Observability is not only about production.
Observability is not only Production Status
We naturally associate Observability with a monitoring panel, with green and red boxes applied to the production environment. This association is partially true for two reasons; Observability applies to all environments, and status is one of the possible measurements.
The Observability pipeline goal is to measure specific business areas while supporting the software development process. Hence, our observability should be applied to all environments to keep a holistic perspective. A significant part of operational improvements comes from upstream improvements.
The second perspective consists of extending the data observed. We are used to looking at states, such as OK/KO or of an absolute value. That’s fine and a first step. The thing is that our systems are in motion, so our Observability must provide visualization for a dynamic process. Value-stream and Process Mining are techniques supporting those requirements.
We can become quite enthusiastic with all those possibilities. However, there are no shortcuts for building an Observability pipeline.
Observability is a step by step approach
We start to grab the complexity of Observability. An incremental approach is a way to equilibrate value creation and risk management, avoiding another tunnel effect initiative. An essential element is to keep our focus on providing value.
Our initial “Why” helps to find the stakeholders’ value in the use-cases. Our initiative must provide early wins fulfilling concrete needs to survive; we must focus on end-to-end Observability increments. A siloed technology approach will just fail sooner or later, even if technology foundations are structuring.
“Scale is not only about scale. It is about creating increasing value with scalable and flexible foundations.”
Antoine Craske
Our first iterations will provide value on a limited set of applications and complexity. Once we start to increase the scope of data, only structured foundations can support the expansion. Shared standards of data formats, schemes, and governance are overlooked; they must evolve collaboratively and incrementally, in line with our Observability initiative maturity.
Foundations are not only technical and come with several challenges.
The challenges of an Observability Pipeline
Providing Observability through our pipeline is about developing a complex ecosystem of data creating value for its stakeholders. We encounter a significant challenge of organizations: human interactions.
Our first interactions start with our stakeholders to identify the why and to ultimately convince them. To fulfill their needs, we require the collaboration of other teams to create our observability solutions. To succeed at expanding, we have to work on culture, a fundamental pillar of scaling engineering practices.
“Culture is a fundamental pillar of scaling engineering practices.”
Antoine Craske
Growth involves increasing the size of the team to accelerate the creation of value. We face a new problem: we need to onboard new members while not consuming the existing teams on training. Valuable documentation can make the difference on top of a buddy, supporting a self-service, scalable onboarding process. The difficulty lies in the structure usability, abstraction level, and stability of the documentation in its various forms (generated by code, wikis, videos).

Technologies also come with a set of challenges. A way to structure the foundations is to provide a developer platform with standards and templates. The difficulty lies in the adoption. Our customers are the developers; traditionally, they prefer their own cook. Our adoption will succeed with an easier usage, by a factor of 10. In addition, a myriad of solutions has to work together to respond to unique needs.
“There is no universal tool to respond to unique requirements.”
Eduardo Piairo
Successfully dealing with the challenges can let us move to the next level of value, such as supporting a Reliability initiative.
A Reliability approach relies on Observability
Ricardo shared with us the focus on a Reliability initiative at Farfetch. The goal is to foster the organization to consider reliable experiences in their digital platforms. Again, measurement is a requirement, relying on Observability.
Reliability materializes in a set of engagement such as Service Level Indicators (SLIs) and Service Level Objectives (SLOs). They can even be a contractual agreement in the form of Service Level Agreements (SLAs). A service level translates into an absolute percentage indicator. The “9” paradigm is a market standard, referred to as “four nines” for 99.99%, for instance.
Service measurement is not limited to their availability or uptime. Google has popularized the four golden signals from their SRE practice. We can find error rate and latency as important as availability. Standards are emerging within the ecosystem to ease our scalability, integration, and interoperability. The “SLOConf” is even a conference dedicated to that theme of SLOs.
Indicators for the sake of indicators are of limited value. We can do better.
An Observability Pipeline for Quality at Speed
We have to understand the “Why” of those measurements. Counter-intuitively, their main drivers were not a contractual perspective linked to financial penalties. Instead, it was a way to support the acceleration and stability of changes. Many human themes are about a balance of contradictory elements; this applies to software delivery through “error-budget”.
The concept of “error-budget” as a credit for the team they can consume while introducing changes can impact service level. Once the credit is consumed, they cannot deploy anymore until the next reset of the counter. During that time, they can address root causes of service disruption, improve their application, and reduce their technical debt. Google is one of the principal initiators of those practices to scale and accelerate their innovations.
The combination of those principles is powerful if we succeed with our Observability pipeline.
Which guidelines to start an Observability Pipeline
Pedro was wondering about the steps to initiate an Observability and Quality initiative. Like any process, contextual elements are fundamental, supported by a set of good practices. We outlined vital steps.
We have to find the sense, reason, motivation in the Why. The Why must be linked to creating value for someone, the concept of quality. The someone is not only one; a broad set of stakeholders are necessary: our users, customers, sponsors up to the different teams. We can articulate a valuable proposition only by understanding each perspective; hence, the importance of involvement.
“Start with Why and for Whom. Then focus on the sponsor and “early win” team.”
Antoine Craske
The various stakeholders need engagement from the start of the initiative. The level of engagement varies depending on a traditional stakeholder matrix. However, two crucial stakeholders are structuring: the sponsor and the “early win” team. The sponsors are the ones who will invest, defend and support your initiative if they capture value. The “early win” team is fundamental to reach results and embark the rest of the organization later on.
“There are two reasons to invest: to win money, or stop losing money.”
Eduardo Piairo
The following steps must follow an iterative approach to balance value creation and risks. Significant risks lie in the challenges of cultural changes, foundations, and scaling capability we identified. The content of each iteration is up to your context, going back to the value, for whom, and its measurement. “Communication, communication, and communication” is fundamental.
Measurement and communication made us circled back to the need for Observability.
Observability at the heart of QAOps
Our conversation of building an Observability pipeline leads to value creation, scaling, and organizations. We materialize the need for business drivers from the start and through our initiative. Courage is required to sustain such a dynamic.
We need the courage to share and understand different stakeholder perspectives while aligning our technology foundations. We need the courage to find a sponsor, foster an engineering culture that can scale, and communicate regularly.
We need courage through all the setbacks we will encounter during our journey. Courage is also required when implementing an error budget, prioritizing mid-term sustainability over short-term feature delivery.
QAOps and its Observability pipeline create value for people through the combination of architectures, organizations, products and technologies. So let’s keep a holistic and incremental perspective, without forgetting the “First things First” principle.
References
Practical Monitoring: Effective Strategies for the Real World, Mike Julian https://www.amazon.com/Practical-Monitoring-Effective-Strategies-World/dp/1491957352
SLO Con, Service Level Objective Conference https://www.sloconf.com
Implementing Service Level Objectives: A Practical Guide to SLIs, SLOs, and Error Budgets, Alex Hidalgo https://www.amazon.com/Implementing-Service-Level-Objectives-Practical/dp/1492076813
Google Golden Signals & SRE approach https://sre.google/sre-book/table-of-contents/
https://blog.qatestlab.com/2019/04/16/trends-2019-qaops-in-software-testing/
https://speakerdeck.com/tylertreat/the-observability-pipeline https://cribl.io/blog/the-observability-pipeline/