
The debate between monorepo and multirepo is often lively between the teams.
To complicate the task, variations of the core models have appeared, sometimes trying to please everyone.
The reality is that a repository is only the storage of the source code, even if a structuring part in its integration and impacts the rest of the processes.
This article aims to take a step back on the subject of repositories: their characteristics, definitions and various options.
Join the QE Unit for more exclusive community content.
What is a repository?
Your repository is the storage of your source code.
A code that has become for a good number of companies one of their main assets, without necessarily realizing it.
Google, for example, has accumulated since 2015 the impressive volume of 2 billion lines of code representing 84 Tb of storage.
It is in fact through this growth, the tendency towards entropy and the extension of the source code that we need to organize its storage.
Like photos or books that we accumulate, structuring their storage in albums and bookstores is necessary in order to remain usable.
We face the same challenge in the software industry, adding technological components to it.
Is a repository only the storage of code?
As such, yes.
For what it isn’t, you can check out this article on the x resting myths.
Why is it such an important topic of choice?
The storage of the code and its organization remains complex by its integration with the rest of the ecosystem.
The organization of code storage between files, projects, libraries will materialize the interactions necessary for the evolution of the source code.
Its structure must be usable by the different teams.
This structure will impact the communication mechanisms, development process and so on.
Access to code is what ends up being used by developers in their development environment, downloaded locally, or configured in CI/CD pipelines.
It should be kept in mind that a choice of a repository organization is structuring for the achievement of the objectives globally pursued.
What are the various options?
Let’s take a step back to get a better overview.
At the heart of the subject of repositories, several options emerge at different levels.
We have 2 structuring options for the organization of the source code:
- Centralized, also known under the term “monorepo”
- Decentralized, corresponding to the “multirepo” model
These alternatives are applicable at several levels in software architecture:
- Globally for the entire code source of an organization up to the storage of the project or of an isolated function
- Transversely by the storage of transversal functions and shared between different projects
- For business application code, test and infrastructure (since managed in As Code) or other files
The following 4 organization-wide models emerge in the industry:
- “Monorepo” (or “one-repo”, “uni-repo”)
- “Multirepo” (or “many-repo”)
- “Hybrid-repo”
- “Split-repo”
Do you feel you have too many alternatives?
Luckily, we have avoided the various variations of “repo”, “-Repo” and “Repository” for the sake of readability.
What is a Monorepo?
Let’s start with the famous completely centralized model, the monorepo.
A monorepo (mono repository) is a single repository that stores all of your code and assets for every project.

This was historically our only option in a world of Mainframes and other systems that have become today’s legacy.
Decentralized architectures such as SOA or microservices have caused it to lose interest, probably wrongly.
Keep in mind that monorepo is the organization and storage of code, without directly being the architecture of the application.
A monorepo can therefore be made up of several different projects, applications and technologies more or less coupled by shared services or libraries.
Storing all of its source code does not mean that we have to compile the entire project with every change.
Strong coupling of the deployment cycle and the repository materialize in the case of an application monolith stored in a monorepo.
Moreover, trying to store an application monolith in a multirepo does not seem the most suitable option at first glance.
So let’s move on to its opposite, the multirepo.
What is a Multirepo?
Let’s also start with a line of the definition of this completely decentralized model.
Multirepos uses multiple repositories for the source code management version control system.

A multirepo organization involves several elements:
- The use of several repositories, often one per application
- The absence of code dependency directly between projects (theoretically?)
A mix of versioning system technologies is therefore possible, for example between Git and SVN, although this has other impacts on the integration chain.
It is a model that has been widely adopted since the distribution of applications, without necessarily being a balanced choice.
The internal organization of each repo, project and its directories remains to be structured.
Keep in mind that a decentralized system will tend to optimize itself locally, sometimes to the detriment of your overall system.
The multirepo is not to be confused with another so-called “Hybrid repo” model or its mutant, the “Split repo” described below.
What is a Hybrid repo?
A “Hybrid repo” is based on the mixed-use of mono and multirepo models.
Hybrid repos use a combination of repositories, some being a monorepo and others being multirepos. In the end, they still store the source code of various projects.

A “Hybrid repo” can be limited to the storage of an application monolith in monorepo, while distributed services will be in multi-repo.
Additionally, a hybrid repository can support the sharing of functions and libraries between teams.
So we finally come back to a monorepo?
Not in this model, the shared libraries must remain quickly compilable and the repository of moderate size, for example, the size of a team.
Does this sound like a shaky choice to you?
It is true that we wonder why we choose multi-repo to finally achieve the objective of monorepo: direct code sharing.
The split-repo model is an alternative to this need.
What is a split-repo?
We will often find the acronym “read-only” associated with split-repo.
A split-repo is a monorepo, used for code storage, that is split into read-only repos for building and releasing project artifacts independently.
Antoine Craske
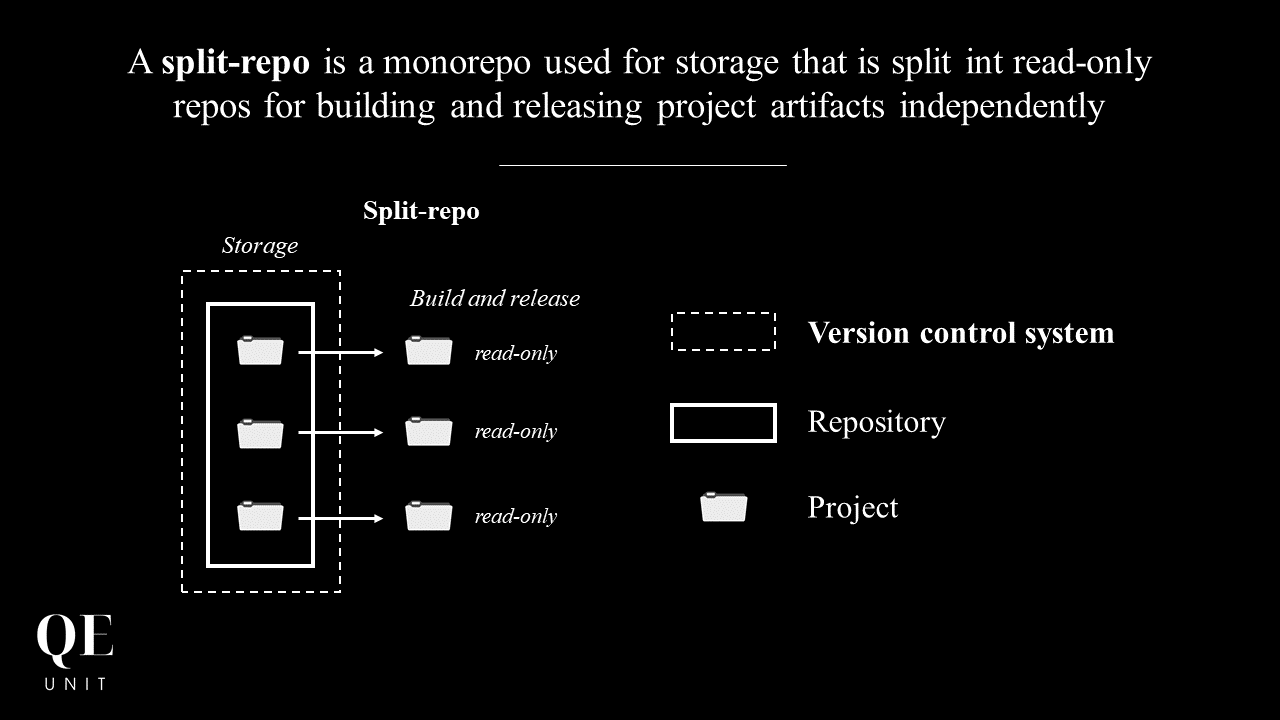
We understand that the split-repo is a model that wants to combine the advantages of the two main models:
- The monorepo for centralized code storage allowing the sharing of libraries and integration as soon as possible
- The multi-repo in order to carry out more granular, independent and faster deployments
As for an IS, we find in the “ready-only” multi-repo the concept of the owner of the data and of various replicas to guarantee its consistency.
It is a model often chosen by organizations preferring a monorepo model but strongly requiring to isolate deployments by technology.
What to remember from these different repo models?
The objective of this article was to provide the overall perspective and description of each of the models.
The main points to remember:
- Your repository is the storage of your source code
- Your repository is not your deployment chain, model branching, dependency management, review or communication process
- Your repository model of choice is structured as closely integrated into the development process
- Two main alternatives exist: centralized and decentralized
- There are four choices: single repository, multi-repo, repo-hybrid, split-repo
Actors across such that Google is efficient with monorepo, while Netflix is efficient on a multirepo model.
There is therefore not necessarily a magic formula, for example, to choose a model according to the size of companies.
How to choose between those different repos options?
The choice of repository model should therefore be taken according to the current and future context of each organization, its objectives while getting organized to manage its trade-offs.
This is a good subject for reflection, even for the test repo where You Can Overcome The Test Repo Dilemma. Now.
References
https://medium.com/@mattklein123/monorepos-please-dont-e9a279be011b
https://hackernoon.com/ mono-repo-vs-multi-repo-vs-hybrid-whats-the-right-approach-dv1a3ugn