
Choosing a repo model is strategic for organizations whose source code is one of their main assets.
Google has made structuring choices about the organization of its repositories since 1999. Choices that have proven to be good at the light of their performance.
What choices has Google made? For what reasons? What organization had to be put in place to support such decisions?
We address these questions to understand and draw possible parallels that are relevant to our organizations.
As an introduction to repos, you can consult this article The Hands-on Mainstream Repo Models You Need To Know.
Follow the QE Unit for more exclusive Quality Engineering from the community.
The repository context at Google
Like any business, Google got off to a good start with a few lines of code.
Google uses the single monorepo for 95% of its single source of truth codebase, leaving Google Chrome and Android on specific ones.
Historically under CVS, the source code was quickly migrated to Perforce.
The first engineers ardently defended a model of monorepo centralized on a monolithic architecture, a choice that was still traditional at that time.
Google teams had not necessarily planned to create one of the world’s largest and most valuable repositories.
Google’s heritage and active asset are of considerable size:
- 2 billion lines of code representing 86 Tb of storage
- 40,000 commits per day by more than 10,000 engineers (and not only)
- More than 35 million commits logged since the 2000s
Here are the impressive detailed statistics from their repository as of 2015, for which more recent data is challenging to obtain.
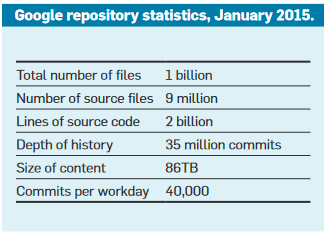
The number of files counts those of configuration, documentation, and those deleted, explaining this high volume.
For comparison, the open-source Linux kernel is on the order of 15 million lines of code with 40,000 files.
The development and growth of Google have resulted mainly in the sustained activity of changes to its repo.
Google’s monorepo scaling
Like New York, Google’s monorepo never sleeps.
Centralized and shared with more than 25,000 developers today, Google has iterated to improve its ability to scale the codebase.
In a typical week in 2015, approximately 15 million lines and 250,000 files were subject to change.
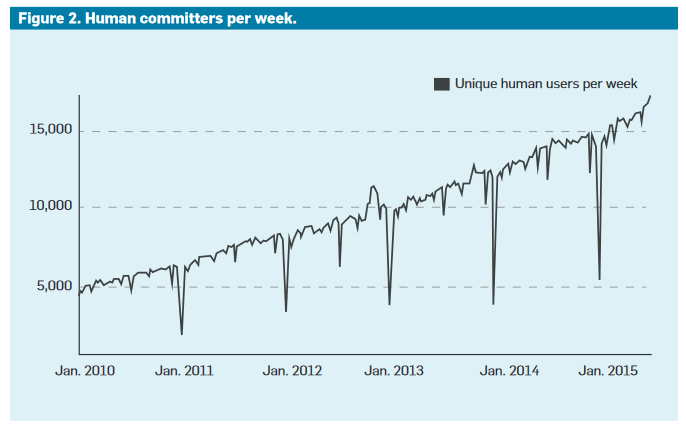
This change volume is impressive in terms of its absolute value and constant growth, especially on a monolithic architecture.
A monorepo on this type of architecture raises real organizational questions, for example, conflicts, which we will discuss in the second part.
However, this impressive performance was not enough to withstand the cycles of accelerated innovations of Google.
Google has raised the bar even higher by surpassing 35 million changes.
We are also seeing a peak in the period preceding 2015, followed by a continuous acceleration.
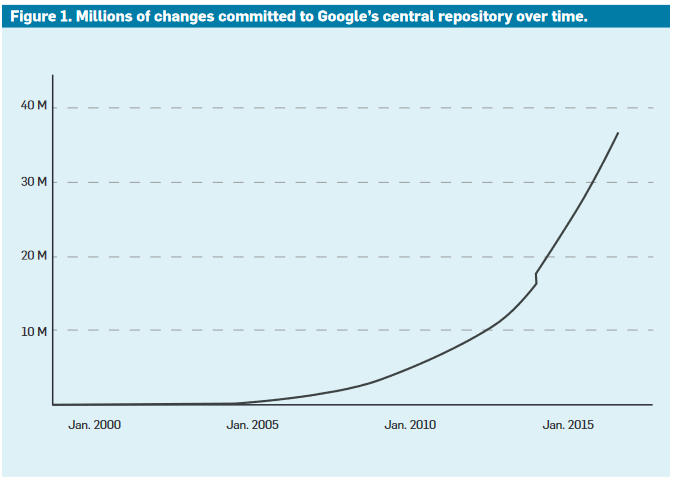
The expression “(and not only)” takes on all its importance here.
The near exponential growth in code activity is not of human origin but from automation.
More than 24,000 changes are made daily by automated systems, making an average of 500,000 requests per second.
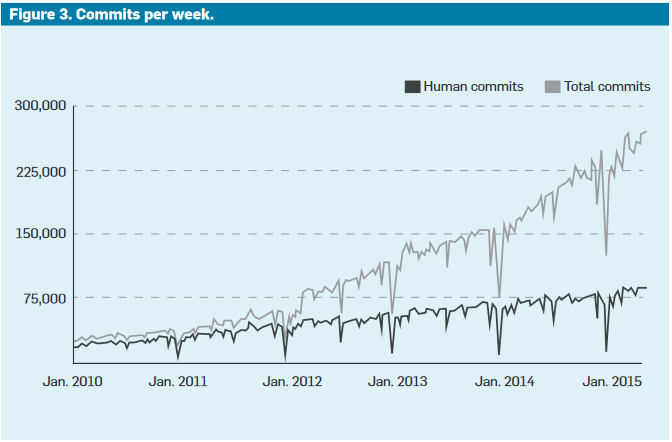
Why use automated commits?
I assure you, we are not (yet) talking about automatically generated functional code.
Google has built over the years an ecosystem of solutions to meet these challenges of growing their monorepo.
What system supports the repository of Google?
Google has built a whole system to meet the various challenges of its monorepo.
The classical difficulties of a monorepo are as follows:
- A long time to download the repository
- Slow and frustrating ways to search or find files
- Less emphasis on good modularization of the code
- The management of dependencies which can become cyclical
- The difficulty in orchestrating the process of build
- Test cycles made more complex by these other factors
So let’s look at how Google responds to these different issues in their order of use.
First, let’s keep in mind that the organization, culture, and communication at Google has always supported a monorepo model: single codebase, sharing, transverse visibility.
Its alignment results in frequent commits to the codebase, where the size of the repository is a primary challenge.
Piper stores their 86 Tb of source code, a distributed storage solution at scale, supporting more than sustained request volumes.
Access is by default open to all developers with integrated traceability. Some files are, by exception, restricted.
While contributing to it, CitC (“Client in the Cloud”) supports browsing Google’s massive codebase with cloud storage and a lightweight interface.
CitC is a proxy downloading locally only modified files.
The search case in this massive repository is supported by CodeSearch, facilitating the search between the different workspaces and simplified edition mechanisms.
An Eclipse and eMacs IDE plugins simplify the development experience.
These three elements allow collaboration at scale on a monorepo, where architecture and delivery processes are central pieces.
What organization of the Google repository?
The architecture and organization of the repository are not linked to the choice of mono or multi-repos but remain structuring.
Check out this article if necessary for a reminder of repo myths.
Google organizes its monolith in different directories known as workspaces, with each having a team and a responsible engineer.
Modularization, interface, and service standards enable communication between the different components. They secure naming, versioning, protocols by use cases, error management, and so on.
API documentation practices and static analysis tools pro-actively support dependency management, which we will cover later.
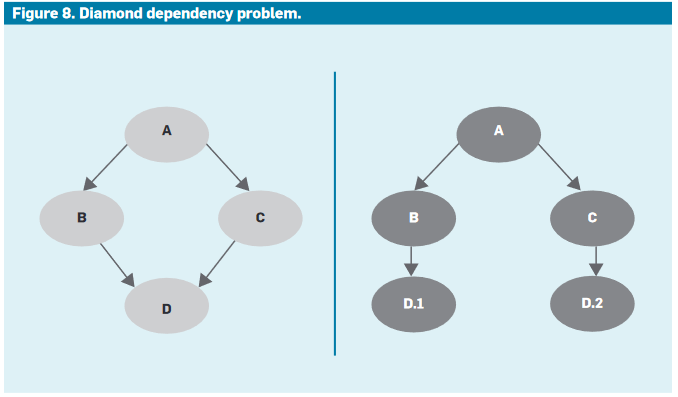
Downstream, the tooling supports the dependency analysis, making it possible to assess and deal with transversal impacts. Monorepo also facilitates a complete repo analysis by avoiding the problem of cyclical dependencies or “diamond-dependency”.
Google also requires a supporting branching model.
Which branching model does the Google repo support?
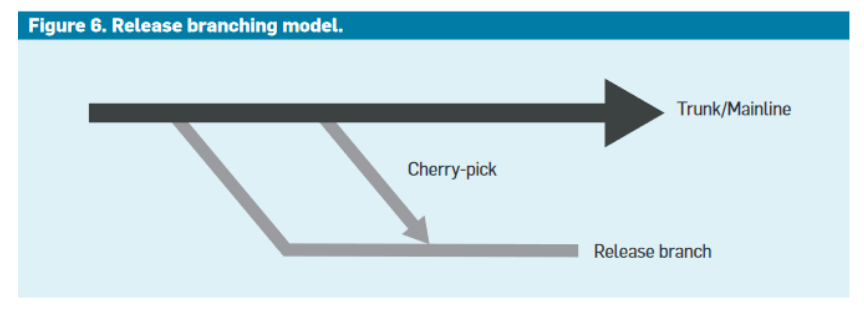
Google is also known to use a trunk-based development model at scale with success.
This model rhymes with a culture of commits and regular deliveries, reducing the integration risks with early verifications.
In terms of branches, changes are pushed to the main branch and submitted to a series of review processes.
This monorepo with a trunk-based branching model removes the merge nightmares from development branches.
The release branches host the deployments usually performed with A/B testing and feature flags. Their purpose is to manage the risk of deployment and not to block the mainline.
Aligned with the model, Google has invested heavily in the static analysis, code cleanup, and review processes.
Each change detail the changes made before being submitted to several validation stages.
What are validation and review processes used?
Their presubmit system, Tri-corder10, carries out the first automatic checks.
Standard and repo-specific controls provide rapid, initial automated feedback to the developer, regardless of their location and time zone.
These verifications result from several years of iterations, incorporating mechanisms similar to development branches that perform localized tests on the impacted components.
The various checks are carried out periodically in addition to each change proposal.
The code is then reviewed, commented on, and possibly reworked before being accepted via a “commit approval” by one workspace owner.
Critique is a Google tool supporting the code reviews process of submission, comments, validation.
The validation step automatically triggers the commit on the repository, where a series of tests will follow.
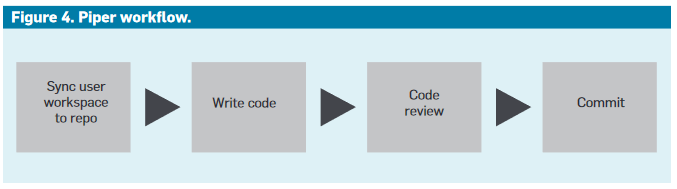
Are we finally getting to the build of our code?
We can refer to the Google-wide build and test tool, Pipe.
A change deemed too risky automatically withdrawn the commit so as not to impact the overall build.
The process described is to be imagined at scale with hundreds of commits per hour.
Perform refactoring on such basic code can be like trying to rework a vast city, a real challenge, and sometimes a nightmare.
How does Google refactors a monorepo at scale?
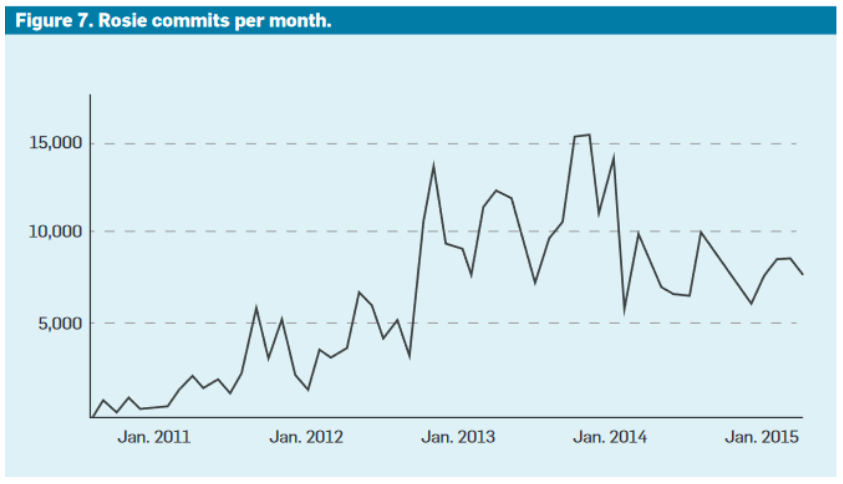
Rosie is the Google solution for performing massive refactorings, optimizations, and code cleaning.
Rosie is at the service of engineers who can make structuring patches on the entire repository.
The solution will secure the riskiest, most time-consuming, and least added-value actions through automation.
Structuring patches are, for example, divided into more minor changes that will be reviewed by each owner before being built and tested independently.
It is interesting to note that the change proposals are reviewed by a committee balancing the necessary review effort, the impacts on the repository, and the value created.
This scale-up review process was put in place in 2013, stabilizing the volume of changes managed by Rosie.
In addition, a team is responsible for maintaining an up-to-date, usable, and efficient integration chain of the compiler.
Google has, therefore, structurally invested in a holistic code management system to meet the challenges of a monorepo at scale.
We need to take a step back to balance such a system.
What are the advantages of a monorepo at scale?
Let’s identify the advantages and disadvantages to have a transversal perspective of the subject.
Google benefits from several structural advantages of its repo:
- Transversal visibility of its code assets
- Centralized and integrated versioning as soon as possible
- Support for code sharing and reuse
- Simplified dependency management
- Atomic changes that remain under control
- Ability to perform structural changes
Their ability to provide a satisfying development experience is vital. Endless loading times, arduous impact analyses, and fear of cross-functional refactoring are gone.
Their ecosystem allows an unprecedented speed of updating their code, supporting a massively extended collaboration.
The use of static linking also solves binary issues, leaving room for quick integration of simple changes if they successfully go through the various stages of review.
How to deal with the disadvantages of a monorepo model?
Google addressed the main disadvantages of a monorepo model to succeed.
Google classifies these pain-points into three categories:
- The complexity and size of the codebase, which makes it difficult to understand, search, scale, and maintain
- Investment in tooling throughout the chain, from the repository to the build, test, and deployment
- Quality management of the repository, code, documentation, and refactoring management
The various shared elements have improved the problems usually encountered with a monorepo, but two main difficulties remain.
The first is that teams tend to consult the implementation details of the various APIs, which are available in the repository.
It is a particularity to accept and align in the culture and practices to avoid restricting accesses. Shared visibility being a strong point of a monorepo.
The second difficulty is the development and integration of open-source components. Google achieves this by keeping a specific space in its repo for its uses. It requires special attention in the context of monorepo.
Will Google switch to a multi-repo model?
Google engineers have regularly wondered about multi-repos and the use of Git.
Android, Chrome, and major open-source initiatives use a multirepos model.
Google could better capture the community’s attention through the widespread use of Git.
Why not replace Piper with Git for their monorepo?
Git supports a distributed development model, mainly in multi-repo.
Using Git would therefore amount to switching the monorepo to a multirepo model, the opposite objective of Google’s organization.
Over the years, despite having asked the question several times, Google’s monorepo has remained the chosen option.
Since 2015, Google has nevertheless been working with the Mercurial community to facilitate team workflows.
What to remember and apply from the Google repo model?
The strategy of monorepo and a monolithic architecture supported Google’s performance.
A structuring point is the alignment of this strategy with the organization, culture, and processes of the organization.
The identification, management, and improvement of trade-offs are also crucial to limiting the constraints and limits of the chosen model.
This global perspective is what allows us to make strategic investment choices.
Keep in mind that adopting a monorepo or a monolithic architecture will not make us the next Google.
The entire system enables a successful orchestration of a business-driven organization.
References
References 1. Bloch, D. Still All on One Server: Perforce at Scale. Google White Paper, 2011; http://info.perforce.com/rs/perforce/images/GoogleWhitePaper-StillAllonOneServer-PerforceatScale.pdf
Build in the Cloud: How the Build System works. Google Engineering Tools blog post, 2011; http://google-engtools.blogspot.com/2011/08/build-in-cloud-how-build-system-works.html
Wright, HK, Jasper, D., Klimek, M., Carruth, C., and Wan, Z. Large-scale automated refactoring using ClangMR. In Proceedings of the IEEE International Conference on Software Maintenance (Eindhoven, The Netherlands, Sept. 22–28). IEEE Press, 2013, 548–551
Why Google Stores Billions of Lines of Code in a Single Repository https://research.google/pubs/pub45424/